
Bag of N-Gram Document Classification
Published:
Summary
Bag of N-gram document classification on IMDB large movie dataset. Using PyTorch, a default Bag of N-gram model is fit and trained. An ablation study is then performed to optimize the default model, improving validation error and ultimately resulting a better test accuracy.
Report can be found here, and relevant code can be found in this GitHub repo.
Data and Methods
Within this large movie review dataset, there are 25,000 reviews designated for training and 25,000 designated for testing. Both of the training and testing sets are split up into an equal number of positive and negative reviews (12,500 within each sentiment directory). The master code follows the same layout as the report, with matching order and section headers. The data then is fit to a defuault Bag-of-N-gram model following the pipeline:
- Tokenization: In the baseline model, the packages spaCy and string were used to make the text lowercase and remove punctuation. Using this, a function was built to create tokenizations of the train, validation, and test datasets.
- Vocabulary and PyTorch Dataloader: Following the tokenization, a vocabulary was constructed with a default size set to 10,000 that created a token and index scheme for the train, validation, and test datasets. Next an IMDBDataset class was built that takes in the indices and targets for each of the datasets and runs it on a PyTorch loader that returns an array of tensors: data list, length list, and label list. Using the token ID’s and the PyTorch loader, a model is fit using Bag of N-Gram. This model takes in a default embedding size of 100.
An ablation study is performed:
- Tokenization schemes:
- Regular expressions vs spaCy data cleaning.
- Model Hyperparameters:
- N-grams (default n=1): Increasing n from 1 to include 2, 3, and 4
- Vocabulary Size (default = 10,000): Increased vocabulary sizes tested 20,000, 40,000, and 80,000
- Embedding Size (default = 100): Tested at 25, 50, and 150.
- Optimization Hyperparameters:
- Optimizer (default = Adam): Test Stochastic Gradient Descent (SGD)
- Learning Rate (defualt = 0.01): Tested at 0.001, 0.05, 0.1
- Learning Rate Schedule (default = linear annealing): Test exponential decay

After running an ablation study we run a new model with the optimized hyperparameters:
- Tokenization: spaCy Tokenizer with no preprocessing
- n = 1
- Vocab Size = 80,000
- Embedding Size = 25
- Optimizer = Adam
- Learning Rate = 0.01
- Learning Rate Schedule = Exponential Decay
The Optimized Model results in a Test Accuracy of 85.868. Compared to the default model (test accuracy = 80.448), test accuracy rose by more than 5 points, ensuring that this model performs to a higher degree of accuracy.
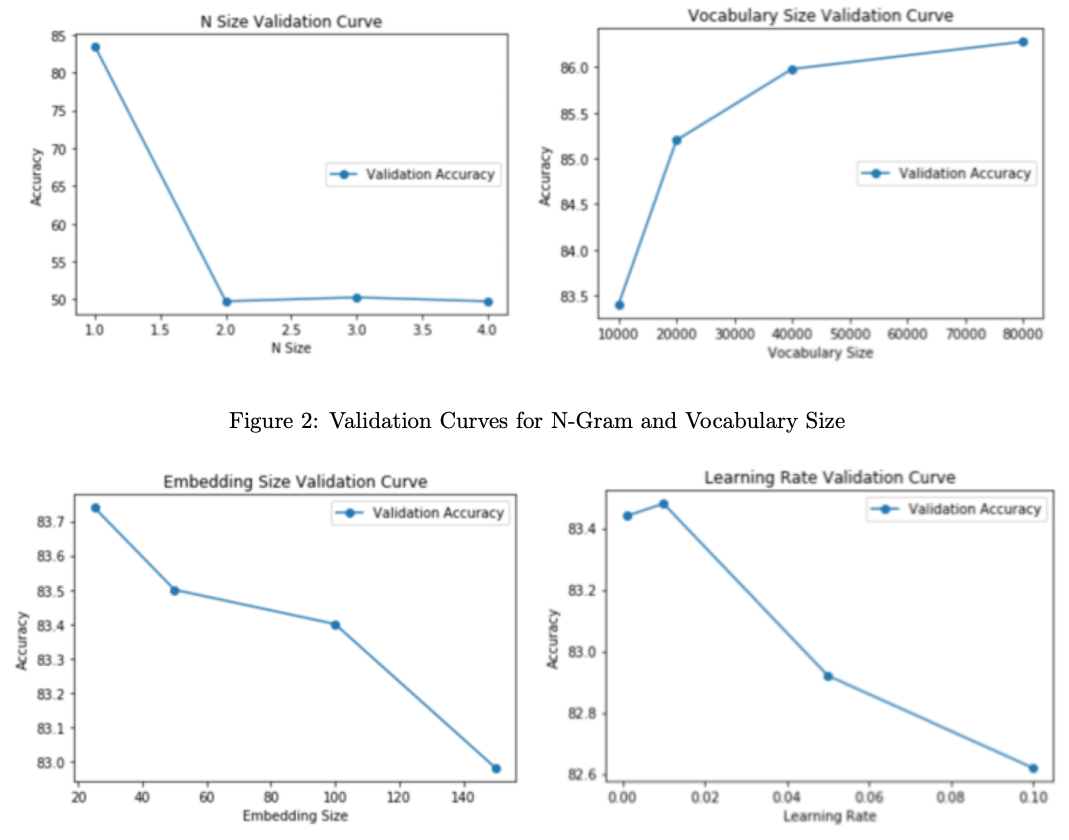
The above shows validation accuracies under the ablation study.