
Unsupervised Data Quality Monitoring
Published:
Summary
Since data engineering as a discipline largely requires extensive cleaning of raw datasets, there exists an increasing need for heightened data quality monitoring within engineering pipelines. We present three methods of unsupervised data quality monitoring that determine, given a chronological series of datasets, whether a subsequent dataset in the series is of acceptable quality. We first establish the Baseline method to determine data quality acceptability, then create two new methods (which we name TFDV and Range) against which to compare the Baseline method. For all three implementations, we compare their accuracies on a model trained with varying batch sizes of training data. Our final results compare the methodologies and discuss the successes and difficulties of the different approaches.
Report can be found here, slides here and relevant code can be found in this GitHub repo.
Data and Methods
The data used consists of a Flights dataset and a Facebook posts dataset, which each have clean data batches along with corresponding dirty batches. The clean data represents data of acceptable quality, and the dirty data represents data that is not of acceptable quality. Our goal is to create a system that determines which data is acceptable and which is not acceptable based on the clean data files only. One of the challenges we face in this project is that the Flights dataset contains one dirty batch and one corresponding clean batch that are significantly different from the other dirty and clean batches in the dataset. As a result, there is not a clearly established divide between all of the clean and dirty data batches.
The problem we focus on answering is determining whether a subsequent batch of data has acceptable data quality. As there is no single characteristic to determine the acceptability criteria, we present here an exploration of various methods that can be used.
For training, we highlight two different training methodologies: Rolling and Increasing. The Rolling method allows for consistency in maintaining batch size and sees if other factors, such as seasonality and recency of specific data batches, provide more details. The Increasing method is useful as it sequentially adds more data to be trained on and allows the model to learn more information as each new batch is added.
To establish a baseline model, we consider a rather naive approach of generalizing the prevalence of null values in an entire data batch. This methodology is established to create a simple and intuitive baseline model that classifies clean and dirty data files. In the next approach, we use TensorFlow Data Validation (TFDV) to determine whether each batch of data is acceptable or not. In general, a single TFDV pipeline consists of inferring the schema from an input data file and then checking if a subsequent data file follows the previously inferred schema. This is done by verifying that the new data file contains the column names of the input file and that the values in each column of the new data fall within the expected ranges or unique values of the inferred data. If this is not the case, then TFDV flags this new file as having anomalies.
In the final approach, we use training batches to create acceptable ranges for specific metrics in order to determine whether a subsequent test batch is acceptable. Our preliminary research suggests that completeness and uniqueness are strong indicators of data quality in a production pipeline. The completeness ratio is calculated separately for every field in a data batch. We define completeness as follows: count of records that have a missing value over the count of records that do not have a missing value. By this definition, we expect a dirty batch to have a higher ratio.
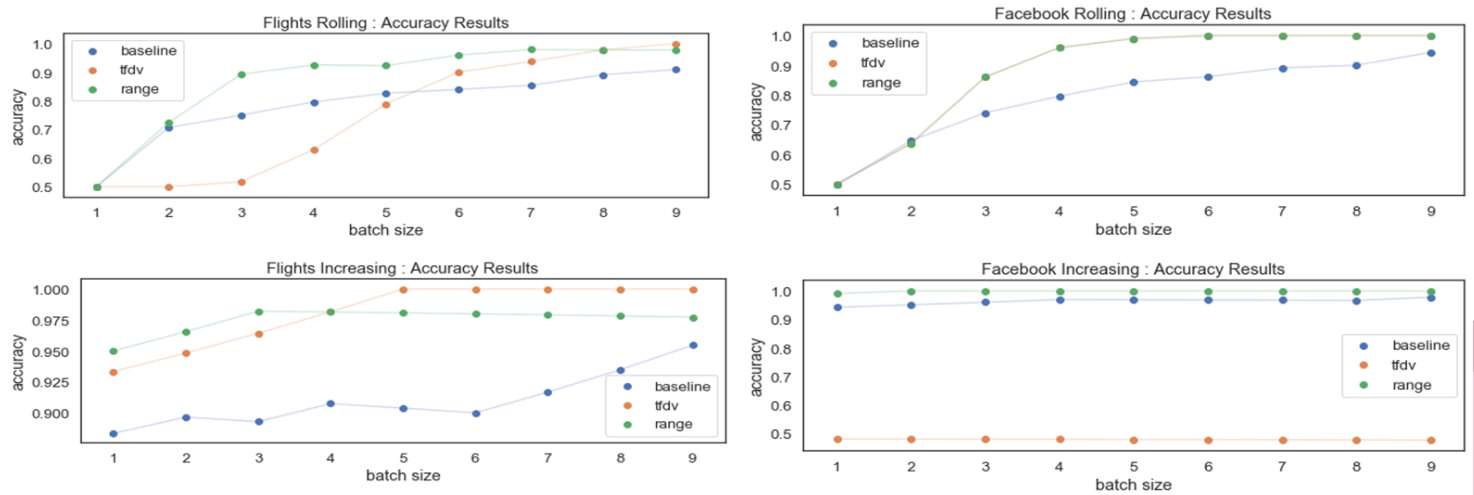
While an increase in training batch size improves accuracy, the plateau (seen above) suggests that there is an optimal batch size that should be used. Using additional batches for training when not required would unnecessarily increase run-time. Similarly, because the Increasing and Rolling training methods end up performing similarly, it would make more sense to use Rolling in a production environment.
Although TFDV outperforms Range with high batch sizes in the Flights Increasing method, generally the Range method was our best performing criterion method. Overall, as batch size increases, accuracy also increases until it appears to plateau. At this point, the accuracy does not improve significantly, meaning there exists a point after which no further training is needed. In classical machine learning terms, this point would be the optimal batch size needed to ensure satisfactory accuracy.