
A Deep Dive into Machine Translation
Published:
Summary
Machine translation is the problem of, given an input sequence in a source language, outputting a translation in the target sentence. We implement our models on two sets of language translation: Vietnamese to English and Chinese to English.
Both sets of translations, Chinese to English and Vietnamese to English, were provided with a set of prepared corpora. The neural translation systems for the two language pairings we cover in this paper are:
- Recurrent neural network based encoderdecoder without attention (Vanilla Encoder Decoder)
- Recurrent neural network based encoder decoder with global attention
- Self-attention based encoder.
Ultimately, we were able to achieve a high BLEU (bilingual evaluation understudy) score of 1.8.
Report can be found here and relevant code can be found in this GitHub repo.
Data and Methods
We trained on 133,317 Vietnamese-English pairs and 213,376 Chinese-English pairs, using the pretokenized preprocessed sentences provided, 1,261 validation pairs for Chinese-English and 1,268 for Vietnamese-English, and tested on 1,397 pairs for Chinese-English and 1,553 pairs for Vietnamese-English. We trimmed, removed and made the input sentences lowercase for English, removing noisy words such as ”apos”. For Vietnamese, we did not remove accents. The vocabulary sizes are 42,153 words for Vietnamese, 66,576 for Chinese, 50,970 English words (with Chinese) and 41,272 words for English (with Vietnamese). Each source sentence-translation pair are clipped at a max length of 20 words per source and target, and padded via batching.
We look to optimize machine translation on the following types of neural models, first using recurrent neural network based encoder decoder without attention, followed by recurrent neural network based encoder decoder with attention, and self-attention based encoder.
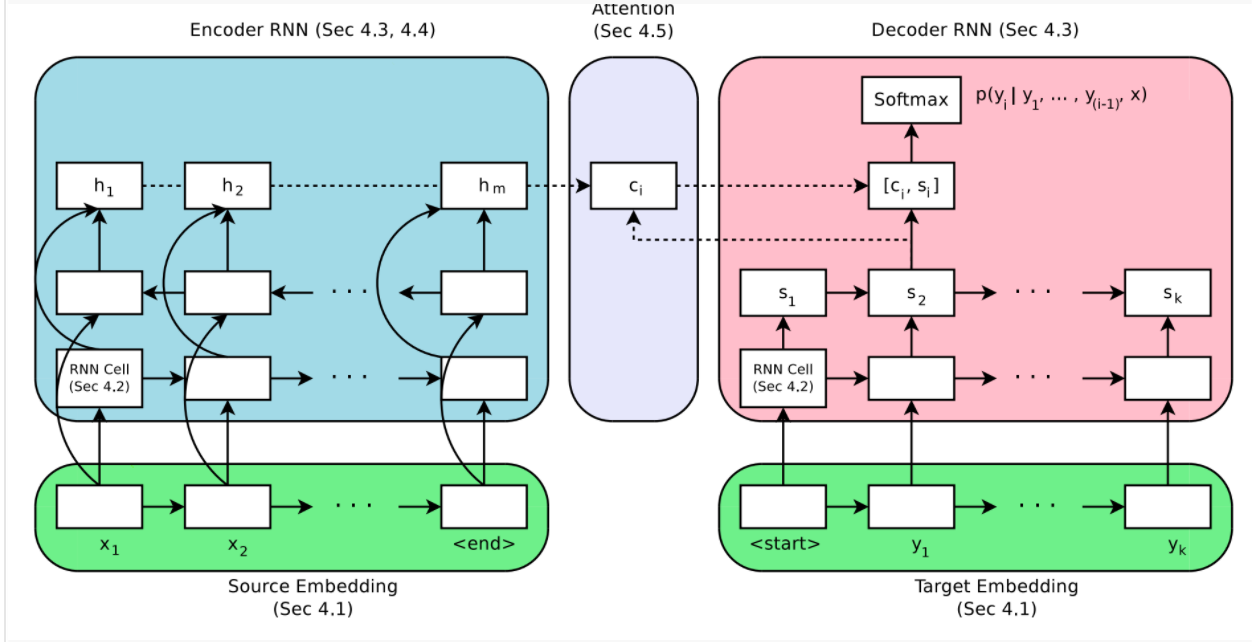
For our experiments, we used a hidden size of 256, running for 4 epochs, calculating validation score with every batch iteration. We used the AdaDelta optimizer. We use beam search with K = 5 (exclusive, without including 1-4), and also set the maximum generation length to be equal to the length of the input sentence. We also experimented with learning rates from 3e-4 to 1, with surprising results, shown in our ablation study of the attention decoder. As clarification, we only preformed the high learning rate on the Luong attention decoder model, not the self-attention encoder model. All other models had a learning rate of 0.01.
We used negative loss likelihood for our train loss, only accounting for the loss with respect to nonPAD tokens in our reference sentence in the batching process. For all our models, we trimmed the length of sentences to be 30, and used sacrebleu’s raw corpus bleu function to calculate the validation and test accuracy. BLEU calculates the geometric mean of the precision of the predicted and reference sentences.
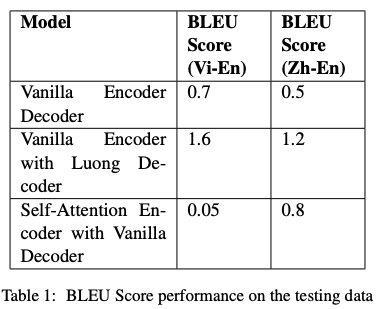
For the Vietnamese to English translation, we were able to achieve a BLEU score was 1.6 and 1.2 for Chinese to English translation with the Luong Attention Encoder model and a learning rate of 1.0.