
Recommender System for User Listening Data
Published:
Summary
For our assignment, we are tasked with using PySpark to build and evaluate a recommender system for user listening data. In general, recommendation systems can either employ explicit data or implicit data to make predictions. Explicit data is feedback voluntarily provided by users such as a star rating of a movie or a “like” on Facebook. Conversely, implicit data is drawn from user behavior such as clicks on an ad or types of items purchased online. The use of implicit data in recommendation systems is becoming increasingly popular and needed as explicit feedback from users is often not readily available in large quantities. Thus, this collaborating filtering approach with Alternating Least Squares makes predictions using data from users and the items with which they have interacted.
Report can be found here, and relevant code can be found in this GitHub repo.
Data and Methods
The data comes from the Last.fm dataset and contains just around a million instances of tracks. For this project, the data is split into training, validation and test.
Beginning by reading in the parquet file and, with a Pipeline, converting both the user_id and track_id columns into integer indices using StringIndexer. Then, using the ml.redcommendation package, we create an ALS model with the default parameters, fit it to our transformed training data, and save the model in HFS. We likewise save the user_id and track_id StringIndexer objects to preserve the mapping when we transform the test data in the test script (als_test.py).
Evaluations are performed on the top 500 track predictions for each user. We join the predicted recommendations with the actual track preferences and pass this information into RankingMetrics. Our evaluation metric of choice is Mean Average Precision, or MAP, which is the mean of the average precision of track recommendations for each user.
Given the size of the data, we decided to dig deeper into the particular model formulations. Given the original structure of the data, we are able to accomplish this by modifying the count data and observing how it affects our MAP estimate.
- The first was to run a standard log compression on the entire count data column. The play counts span a very large range per user per track, from single listens all the way to 9,667 listens. Given the expansive range, log compression can be used to create more linear data and provide a better evaluation space for our recommender system.
- The next alternative formulation considers how low user play counts affect recommendations and their corresponding MAP. We predict that listening to a song only once should have a very minimal, if any, effect on future recommendations.
- We continue exploring how low play counts affect recommendations by dropping all instances from the training data that contain two or fewer counts. For any one track, a play count of two suggests that a user may have been indifferent to a track after the first listen, but listened again an additional time. If after the second listen the user does not enjoy the song, it should not be considered as a positive interaction by our recommender system.
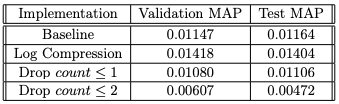
We train a baseline ALS model and three alternative model formulations:
- Log compression
- Drop counts ≤ 1
- Drop counts ≤ 2
Using RankingMetrics to yield the MAP of each our models, we evaluate on the top 500 track predictions for each user on the validation and test set. Out of the four ALS model formulations, the Log Compression alternative formulation slightly outperformed all other formulations on both data sets, with MAP values of 0.01418 and 0.01404, respectively.