
Natural Language Inference using Recurrent and Convolutional Neural Networks
Published:
Summary
The SNLI dataset contains two pieces of text: a premise and a hypothesis. After training a model, predictions will be able to be made labeling the premise as entailing the hypothesis, contradicting the hypothesis, or neither entailing nor contradicting and thus being neutral to it. As this task is based on natural text, ambiguity will be introduced regarding the labeling of each premise and hypothesis pair. After the best model is built, testing on the Multi-Genre Natural Language Inference (MNLI) – a variant of SNLI which covers spoken and written text from different sources, or “genres” – is performed to determine how well the optimal model performs on different genres. The MNLI dataset contains 5,000 validation instances.
Report can be found here, and relevant code can be found in this GitHub repo.
Data and Methods
The SNLI dataset contains 100,000 training instances and 1,000 validation instances. Each sentence is then loaded and tokenized based off whitespace, splitting sentence pairs into pairs of word lists. The premise and hypothesis labels are recoded into numerical values with contradiction = 0, neutral = 1, entailment = 2. Following this, a vocabulary embedding was built using the FastText pre-trained word vector sets. Using the SNLI dataset, a PyTorch training and validation data loader were constructed to train on both a Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) and test validation accuracies.
Default parameters for both RNN and CNN models:
- embedding size = 100
- hidden size = 200
- number of layers = 1
- number of classes=3
- vocab size = id-to-word length
- learning rate = 3e-4
- number of epochs = 5
- criterion = Cross Entropy Loss
- optimizer = Adam
A. RNN: For RNN, we utilize a single-layer bi-directional Gated Recurrent Unit (GRU). Since the task utilizes pairs of sentences (premise & hypothesis) and a bidirectional GRU, hidden size increases by four times the original output. Another important feature of the RNN is that when using a padded sequence for the vector representations, the sentences have to be fed into the encoder in descending sorted order. After doing this, it is necessary to re-sort the sentence pairs to their original pairings before concatenating the final state of the encoder. This single vector concatenation is then passed through two fully-connected layers (with ReLU activation in between) and passed through a testing model.
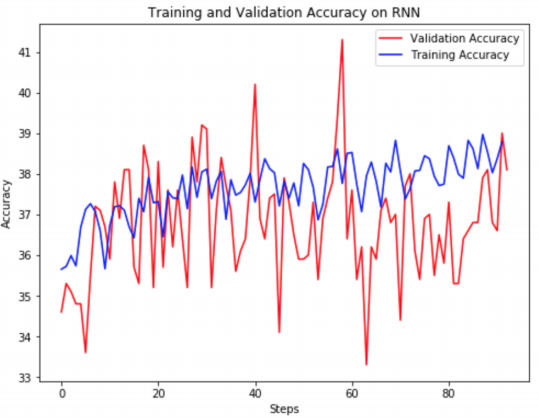
Max accuracies: Training Accuracy: 38.968, Validation Accuracy: 41.3 (a lot of fluctuation present).
B. CNN: For CNN, we implement a two layer one-dimensional convolution with ReLU activations. Since the input data is in pairs of sentences, the hidden size increases by two times the original output. With CNN, sorting the sentences and padding the vectors is not required. Instead, we perform max-pooling on each particular sentence within the pair before concatenating the final state representations into a single vector. This concatenation is then passed through two fully-connected layers (with ReLU activation in between) and later passed through a testing model.
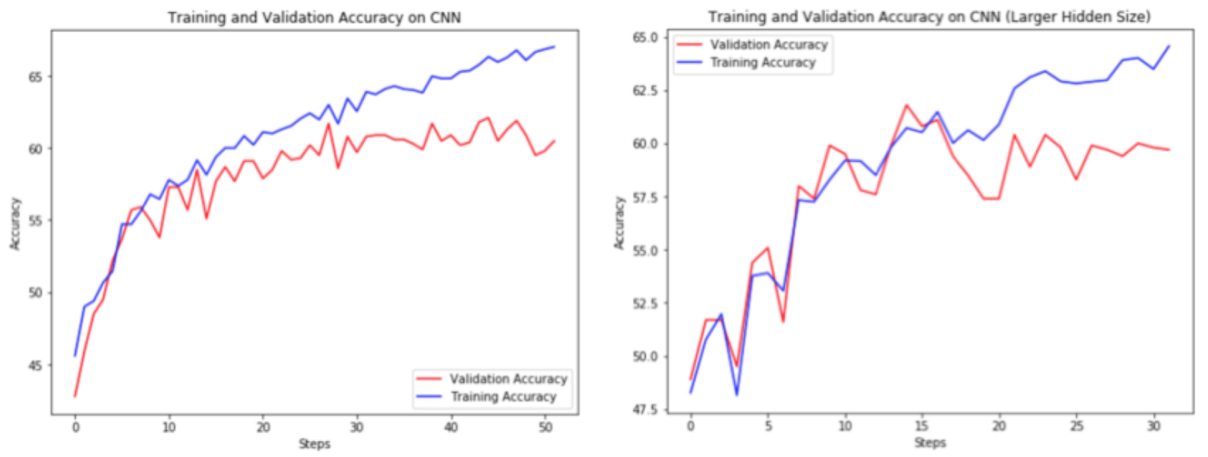
Max accuracies: Training Accuracy: 66.998, Validation Accuracy: 62.1.
Hyperparameter tuning was conducted however performance on the SNLI task did not improve.
After establishing the optimal model, it is then evaluated on an entirely new dataset, the Multi-Genre Natural Language Inference (MNLI) – a variant of SNLI which covers spoken and written text from different sources, or “genres”. There are five genres present in the MNLI dataset: fiction (995 instances), government (1016 instances), slate (1002 instances), telephone (1005 instances), and travel (982 instances).
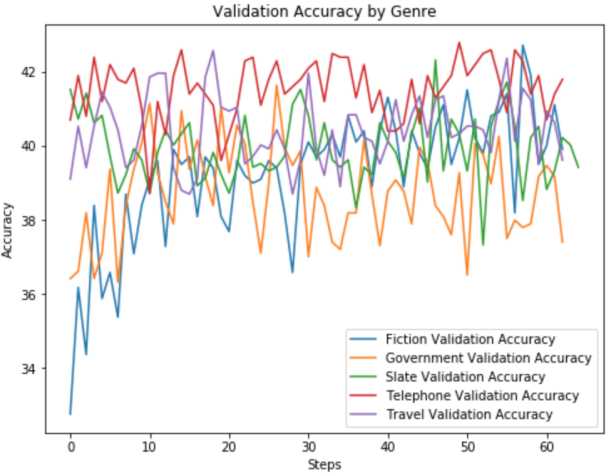
Max validation accuracies per genre over steps:
- Fiction: 42.714
- Government: 41.634
- Slate: 42.315
- Telephone: 42.786
- Travel: 42.566