Spam Classification on SMS Messages
Published:
Summary
For our assignment, we analyzed SMS text messages to classify them as ‘spam’ or ‘ham’. As online communication has adapted and shifted from email to various forms of direct messaging, phishers have adjusted where and how they target individuals with spam. Users want to know that their accounts and data are secure, and they do not have time to be bothered by receiving spam messages.
Report can be found here, and relevant code can be found in this GitHub repo.
Methods
For each of the models:
- Logistic Regression
- Random Forest
- LSTM Neural Network
We performed feature extraction using sparse vectoratization techniques, CountVectorizer and TfidfVectorizer, as well as utilizing bigrams, n-grams and word embeddings to test against a dense vector representation.
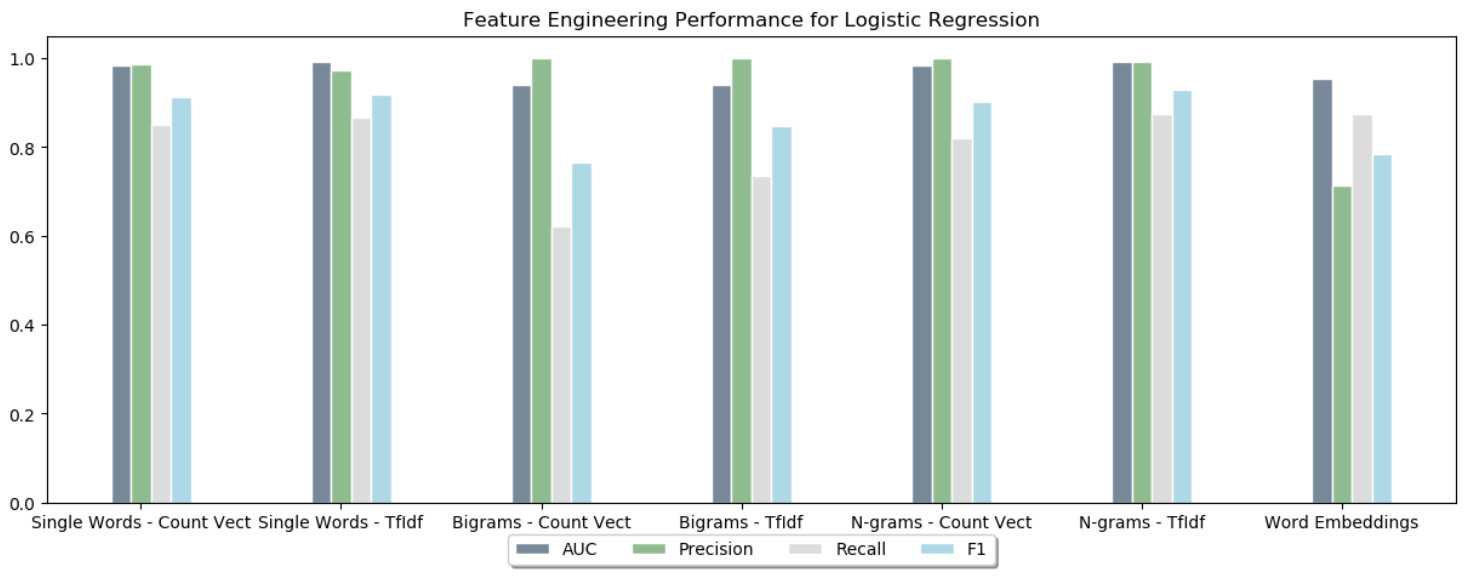
Logistic Regression seemed to perform the best, when used with the n-gram TF-IDF vectorization. It seems that the custom embeddings were not trained on enough data and possibly overfit, so that set of feature engineering did not seem so useful. The random forest models also seemed to overfit slightly, but the performance was comparable to the logistic regression. The LSTM classifier overfit completely.
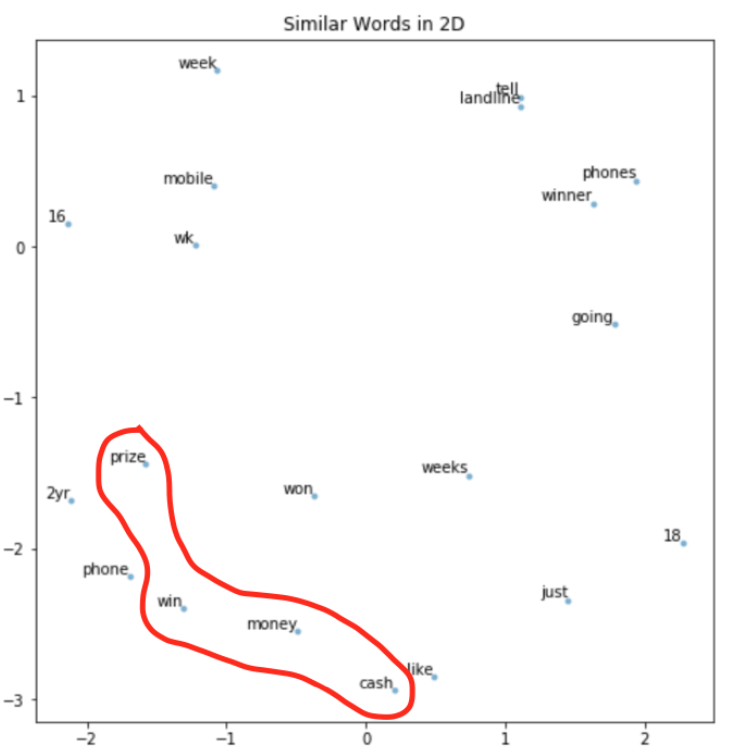
Word Embeddings and Visizualizations
Using the custom word embeddings model, we decided to extract the particular word embeddings and visualize them to see which words are similar. To get the embedding vectors, we utilized the default CountVectorizer with its built-in English Stop Words to build a vocabulary set. Another interesting aspect to analyze is to look at a more formal definition of word similarity. Taking a sample of the first 1000 word entities, spaCy has a built-in similarity method that can give a value, between 0 and 1, for the similarity between two words. Having a similarity of over 0.5 would imply that the two words are in fact similar. However, it is important to remember that similarity to humans can be a highly subjective topic and spaCy’s similarity model utilizes a rather standard similarity definition. The word pairs with highest similarity from the first 1000 word sample are:
- cash and money, similarity = 0.8191
- win and won, similarity=0.8187
- going and just, similarity = 0.8183